University of Oxford
University of Oxford
University of Oxford
University of Oxford
University of Oxford
University of Oxford
The Thirty-Eighth Annual Conference on Neural Information Processing Systems
*Equal contribution
What data or environments to use for training to improve downstream performance is a longstanding and very topical question in reinforcement learning. In particular, Unsupervised Environment Design (UED) methods have gained recent attention as their adaptive curricula promise to enable agents to be robust to in- and out-of-distribution tasks. We investigate how existing UED methods select training environments, focusing on task prioritisation metrics. Surprisingly, despite methods aiming to maximise regret in theory, the practical approximations do not correlate with regret but with success rate. As a result, a significant portion of an agent’s experience comes from environments it has already mastered, offering little to no contribution toward enhancing its abilities.
Put differently, current methods fail to predict intuitive measures of “learnability.” Specifically, they are unable to consistently identify those scenarios that the agent can sometimes solve, but not always. Based on our analysis, we develop a method that directly trains on scenarios with high learnability. This simple and intuitive approach outperforms existing UED methods in several binary-outcome environments, including the standard domain of Minigrid and a novel setting closely inspired by a real-world robotics problem. We further introduce a new adversarial evaluation procedure for directly measuring robustness, closely mirroring the conditional value at risk (CVaR). We open-source all our code and present visualisations of final policies here: this https URL.
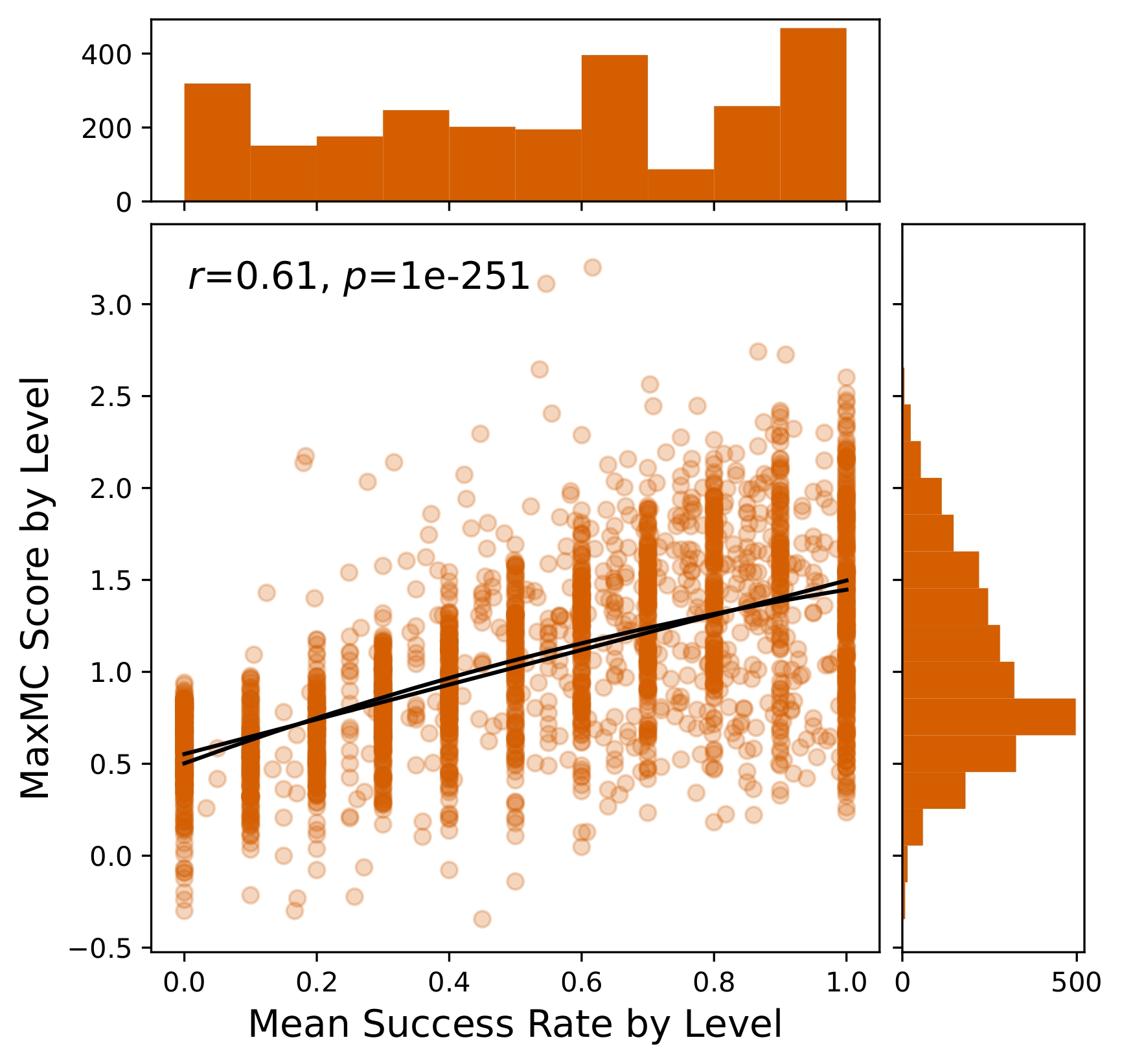
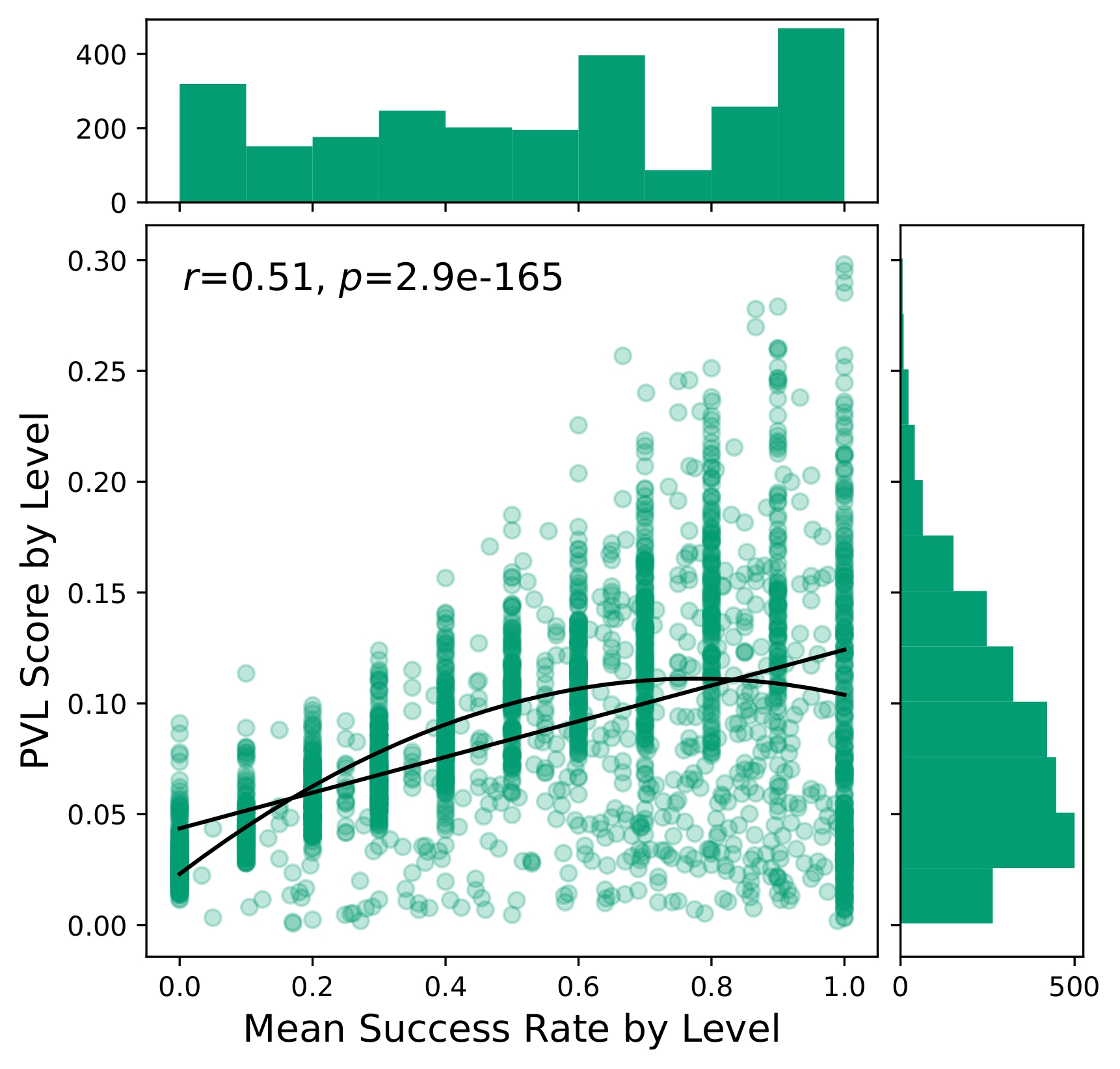
As seen below, two common score functions generally correlate with success rate, and are the highest when the agent perfectly solves a level! We argue that, instead, levels with high “learnability” should be prioritised, i.e. those that are solved sometimes, but not always.
Inspired by this, we use a score function defined as p(1-p). Where for a given success rate p in a deterministic, binary-outcome domain, which is maximised when the agent solves the level exactly half the time. We use this to develop a new algorithm, Sampling for Learnability (SFL), which samples a large number of levels and uses rollouts to evaluate their learnability. We then train the agent on a mix of the highly learnable levels alongside random ones.
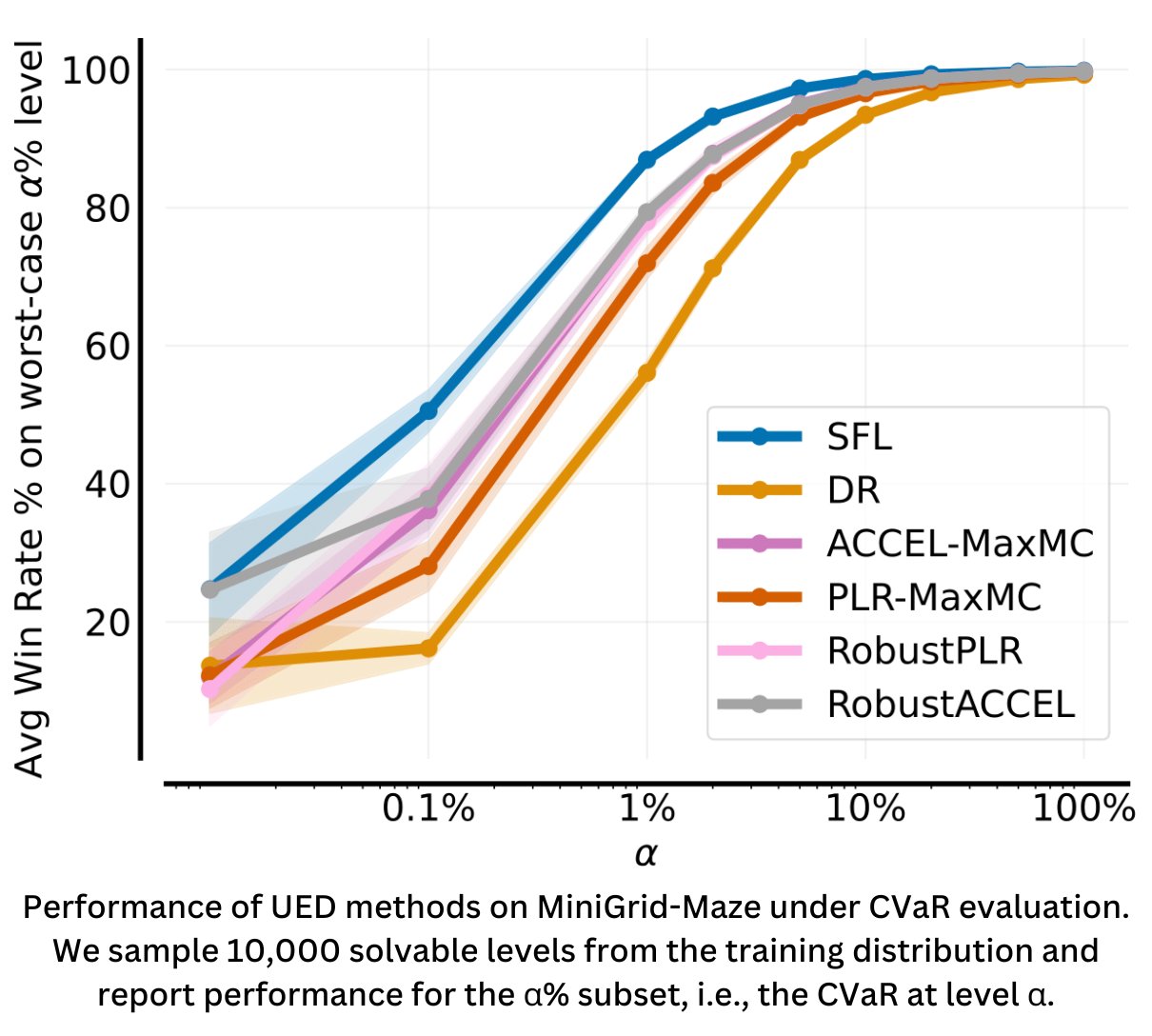
Furthermore, to actually test the robustness of curriculum-learned agents, we propose an adversarial evaluation procedure that better measures robustness. Mirroring Conditional Value at Risk (CVaR), it offers a more rigorous way to assess agents under challenging conditions.
Our results demonstrate that SFL outperforms multiple SoTA UED methods on several domains, including MiniGrid Maze, XLand-MiniGrid and a more real-world environment in 2D robotic navigation tasks.
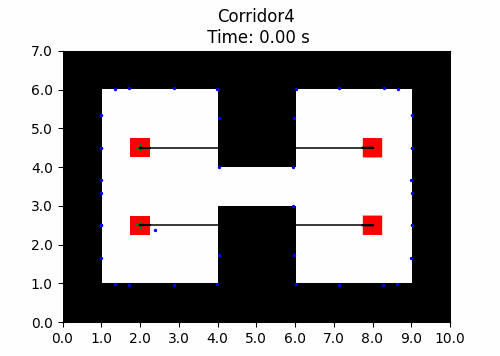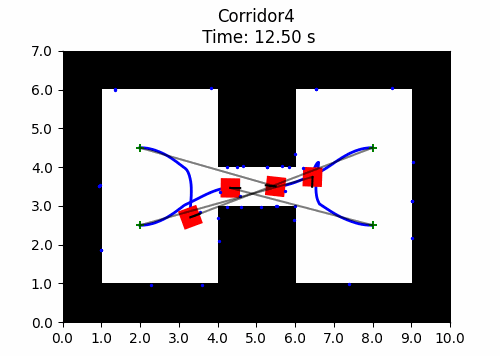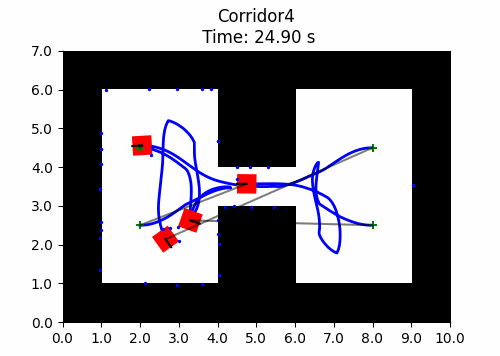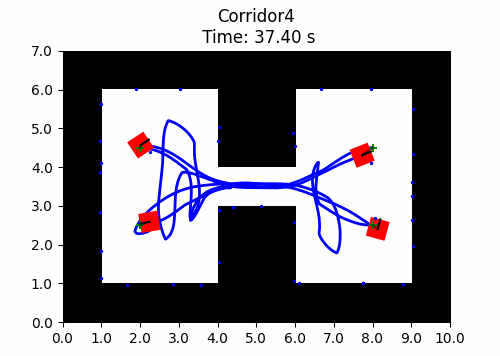
We also introduce JaxNav, a 2D geometric navigation environment for differential drive robots. Using distances readings to nearby obstacles (mimicing LiDAR readings), the direction to their goal and their current velocity, robots must navigate to their goal without colliding with obstacles. In the example shown here, there is no communication between agents, they deconflict and navigate soley based on the aforementioned features.
Kinetix, use SFL to train their general agent, with performance far exceeding other UED approaches, including Domain Randomisation!
@misc{rutherford2024noregrets,
title={No Regrets: Investigating and Improving Regret Approximations for Curriculum Discovery},
author={Alexander Rutherford and Michael Beukman and Timon Willi and Bruno Lacerda and Nick Hawes and Jakob Foerster},
year={2024},
eprint={2408.15099},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2408.15099},
}